Agrotech bot “multi-RAG” sous OpenAI
En 2025–2026, la logique d’enseigner la partie connaissance théorique dans un cursus (même une licence professionnelle, donc très appliquée) s’oriente beaucoup plus vers :
- Un site e-learning structuré : avec un parcours clair, découpé par UE/UV, où les étudiants avancent à leur rythme.
- Des tutos multimédia (vidéo, infographie, simulations interactives) qui rendent plus vivante la théorie que de simples polycopiés.
- Un auto-learn guidé : chaque étudiant peut tester ses acquis via QCM, mini-projets, exercices pratiques, avec feedback automatique.
- Des RAGs par UV (Retrieval Augmented Generation) : l’étudiant pose ses questions en langage naturel (ex. en français ou en malgache), et l’IA va chercher la réponse dans une base documentaire spécifique à l’UE concernée. Cela permet d’éviter les réponses trop générales ou hors-sujet.
A- un bot WhatsApp “multi-RAG” sous OpenAI qui interroge ~10 bases (une par UE/sujet).
Architecture pour ce bot multi-RAG
- Canal :
- Initialement > WhatsApp Business (Cloud API Meta ) dans un premier temps en texte only avec des renvoi asynhcrone de texte avec des liens
- Dnas un 2 ème temps Une WebApp REACT.JS et/ou une APP nativeREACT allans aussi sur le routeur RAG du domaine. Controllant l'UX nous pourrons pousser des images et vidéo en plus de textes mais aussi pouvoir envisager une interaction en temps réel via des partenaires proposant de l'analyse de cessions vidéos en temps réel
- Découvrir plus
- Webhook + Orchestration : petit backend (Node.js/Express ou Python/FastAPI).et en phase 2 connexion direct vers DB ODOO
- LLM : OpenAI (chat + fonctions/outils) dans un premier temps, Gemini, ou QWEN dans un 2 ème temps.
- Embeddings & Recherche : embeddings OpenAI + base vecteur (pgvector/Postgres, Qdrant, Weaviate, Pinecone…).
- Stockage : fichiers sources (PDF/Slides/notes) sur S3/Blob + métadonnées (UE, semestre, langue).
- Observabilité : logs, traçage, feedback des étudiants.
- Sécurité : clés chiffrées, PII minimisée, journalisation conforme RGPD.
Routage vers “une dizaine de RAG” dans un segment précis : l'agriculture
Notre objectif premier va être de faire un service de coach educatif dans le domaine d'une licence Agricole
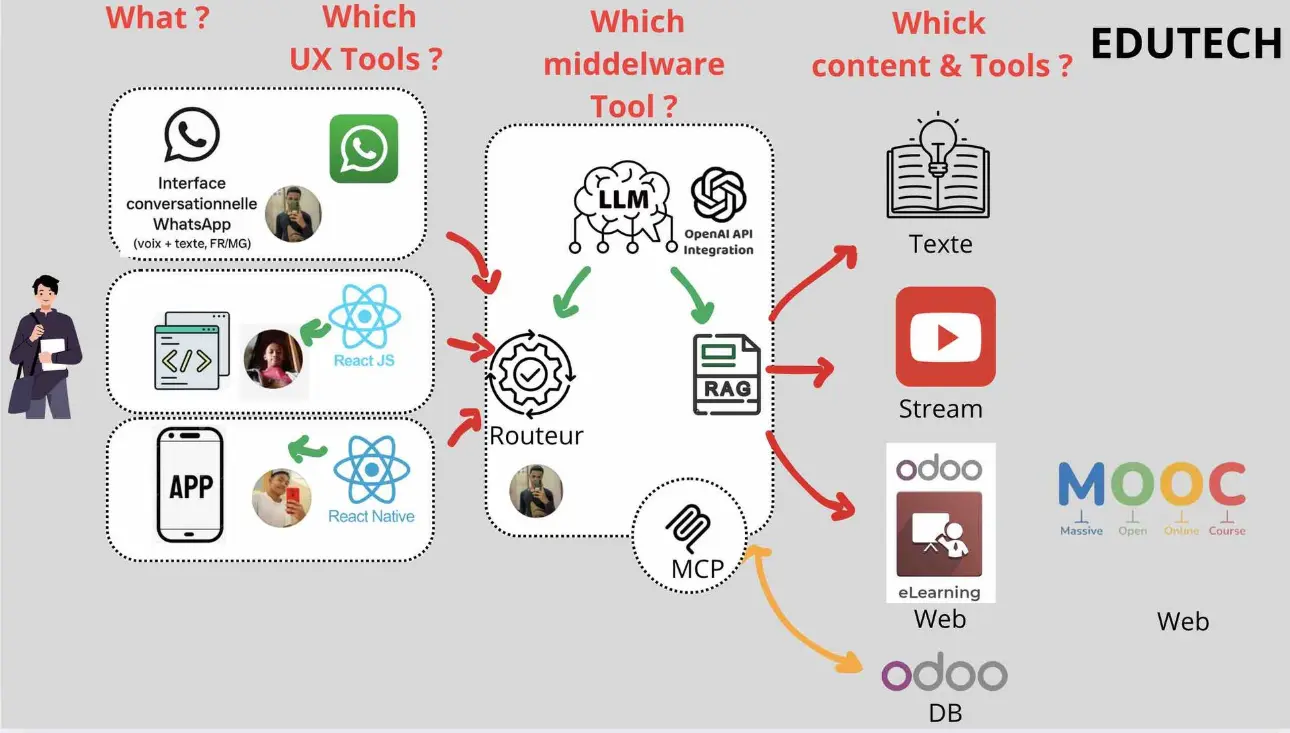
Idée clé : un seul bot, plusieurs “espaces de connaissances” (namespaces) :
- agro:UE1_biologie,
- agro:UE2_sol,
- agro:UE3_irrigation,
- agro:UE4_agroeco,
- agro:UE5_permaculture,
- agro:UE6_economie,
- agro:UE7_machinisme,
- agro:UE8_phytopatho,
- agro:UE9_stats,
- agro:UE10_projets (à adapter).
-
Stratégie de routage :
- Classifier l’intention/sujet (LLM “router” léger).
- Option mixte : requête sur le namespace le plus probable + un “global” pour les réponses transverses.
- Si confiance faible → demander poliment la matière (“Voulez-vous parler d’irrigation ou de sols ?”).
ANNEXES
Flux de traitement (simplifié)
- Message WhatsApp → Webhook.
- Détection langue (FR/MG/EN) + classification du sujet.
- Retrieval : embeddings de la question → top-k passages dans le namespace choisi (+ éventuellement fallback global).
- Réponse LLM avec context window contenant : question, passages sélectionnés, consignes (ton académique, citer sources).
- Réponse structurée (texte court + puces + sources) → WhatsApp.
- Feedback (👍/👎) et journalisation.
Schéma de données (minimal)
- documents(id, title, ue, semestre, langue, url, checksum, updated_at)
- chunks(id, document_id, chunk_text, token_len, embedding_vector)
- Index vecteur par ue (namespace) + langue.
Qualité des réponses (guardrails)
- Citations : inclure le titre du document + page/section.
- Raisonnement : demander au modèle de ne pas halluciner (“répondre uniquement à partir des extraits”).
- Fallback : si info manquante → proposer ressource officielle (plan de cours, polycop, enseignant référent).
- Niveaux : ajouter un paramètre “niveau d’étude” (L1/L2/L3) pour calibrer la profondeur.
WhatsApp : points pratiques
- Fenêtre 24h : au-delà, il faut des templates approuvés (messages “hsm”).
- Types : texte, image, doc, boutons rapides, listes.
- Latence : viser < 3–5 s par réponse (cache des embeddings, top-k=5–8, réponses ≤ 700–900 caractères, puis “Voir plus” avec un PDF/URL interne).
- Multilingue : forcer la langue détectée ou préférée de l’utilisateur dans le prompt.
Empilement technique recommandé
Empilement technique recommandé (option initiale )
- Backend : Node.js (Express/NestJS) ou Python (FastAPI).
- DB : Postgres + pgvector (simple, économique) ou Qdrant (rapide, open-source).
- Stockage : S3-compatible (MinIO si on-prem).
- File ingestion : pipeline qui découpe (chunking 500–1200 tokens), nettoie, extrait tables/figures, génère embeddings, versionne.
- Monitoring : Prometheus/Grafana + traces (OpenTelemetry) + un petit back-office d’annotation (corriger réponses, marquer “bons passages”).
Empilement technique recommandé (option ODOO phase 2 )
- Objectif > Passons à un empilement 100% Odoo-centric (autant que possible) pour votre bot WhatsApp “multi-RAG”
- Backend applicatif : Odoo (modules custom en Python + ORM).
-
Réception WhatsApp :
- soit via un contrôleur Odoo (@http.route) exposant un webhook compatible Meta/agrégateur,
- soit via l’app WhatsApp native d’Odoo (si disponible/éligible) ; sinon 360dialog/Twilio.
- DB principale : PostgreSQL d’Odoo (modèles Odoo).
.
Choix des modèles (indicatif)
- Embeddings : OpenAI embeddings récents (qualité multilingue, cohérence FR/MG/EN).
- Chat : modèle généraliste (précis en FR), avec functions/tool calling pour : classify_subject, retrieve_passages(namespace, query), format_answer.
Gouvernance des contenus
- Source of truth : dépôts officiels (syllabi, transparents CM/TP, polycopiés, bibliographie).
- Mises à jour : ingestion planifiée (hebdo) + invalidation d’index.
- Rôles : admin (Doyen/resp. pédagogique), éditeur (enseignants), validateur (QA académique).
Coûts (ordre de grandeur, à adapter)
- Embeddings initiaux : dépend du volume (ex. 5 000 pages → ~5–10 M tokens).
- Requêtes : chaque question = quelques milliers de tokens (prompt + passages + sortie).
- Stockage vecteur : quelques dizaines d’euros/mois pour 10 namespaces modestes.
- WhatsApp : coût par conversation (Meta) + éventuel agrégateur.
- Optimisations : cache de réponses fréquentes, reranking local (économise tokens), “short answers by default”.
Sécurité & RGPD
- Minimiser PII dans les messages.
- Chiffrer les clés & secrets.
- DPA avec les fournisseurs, mention d’information aux étudiants.
- Journaliser sans données sensibles (hash d’utilisateur + horodatage + sujet).
Roadmap de mise en œuvre (rapide)
- Cadrage : liste des 10 RAG (UE), formats, langues, volume.
- MVP : 2 namespaces (ex. Sols & Irrigation), ingestion + bot WhatsApp de test interne.
- Qualité : consignes anti-hallucinations, format de réponse, citations.
- Extension : passer à 10 namespaces, back-office enseignants, analytics questions fréquentes.
- Production : monitoring, SLA, guide d’usage étudiants, politique de modération.
ANNEXES TECHNIQUES

Proposition de prompt système bilingue FR/MG pour que votre bot WhatsApp
Voici une proposition de prompt système bilingue FR/MG pour que votre bot WhatsApp réponde à vos étudiants en licence agronomie. L’idée est de couvrir
- Le multilingue (FR/MG → détection + réponse dans la langue de l’utilisateur).
- Le cadre académique (niveau Licence, 3 ans).
- La pédagogie (réponses claires, concises, structurées).
- L’intégrité (répondre uniquement à partir des extraits RAG, citer sources).
Version “prompt API” directement utilisable (par ex. pour OpenAI function calling / Node.js ou Python)
version “prompt API” directement utilisable (par ex. pour OpenAI function calling / Node.js ou Python), afin que vous puissiez l’intégrer tel quel dans votre bot WhatsApp ?

Prompt d’évaluation automatique (FR/MG) + un schéma JSON de sortie pour scorer chaque réponse du bot
oici un prompt d’évaluation automatique (FR/MG) + un schéma JSON de sortie pour scorer chaque réponse du bot et, si besoin, demander une réécriture guidée.
Reconnaissance d’espèces et de maladies directement dans le navigateur?
Caméra temps réel intégrée au client React : reconnaissance d’espèces et de maladies directement dans le navigateur via WebGPU (ONNX Runtime / Transformers.js), avec masquage RGPD et envoi uniquement des métadonnées pertinentes.
Double mode de traitement :
- On-device (rapide, privé) pour la majorité des cas ;
- Cloud/Edge via WebRTC + OpenAI Realtime API pour les analyses lourdes, multimodales et le branchement direct sur vos RAGs.
Routage intelligent vers les RAGs par UE : résultats visuels (plante + symptôme) convertis en requêtes structurées vers le bon namespace (ex. agro:UE8_phytopatho), avec fallback via APIs externes (Pl@ntNet / Plant.id) en cas de faible confiance.